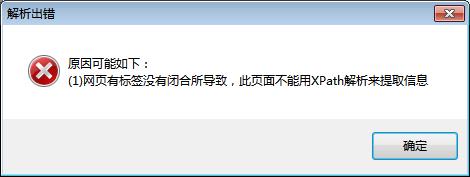
最近在用火车头采集器获取网址的时候,使用Xpath获取网址遇到上述错误,百度搜索一阵,火车采集器官方论坛好像也有网友遇到类似的问题,但好像都没有找到针对该问题的解决办法。按照我的想法这个肯定是html里面代码的问题不适用于Xpath获取网址。
实际上也是这样的,这种情况肯定是采集的目标网页html代码里面哪个标签没有闭合,比如说<div></div>这样是一个标准的闭合的div标签,如果后面的</div>少了,那当然就属于标签没有闭合的情况,这种情况有时候并不影响网页浏览,前端或许会有很细微的变化,不查看网页源代码也看不出来。
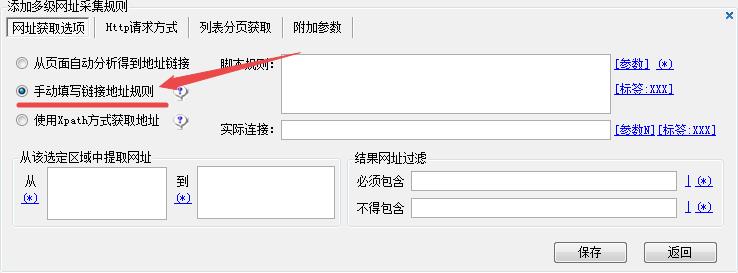
因此碰到这个问题一般用手动获取网址,选择下图的手动填写链接地址规则。
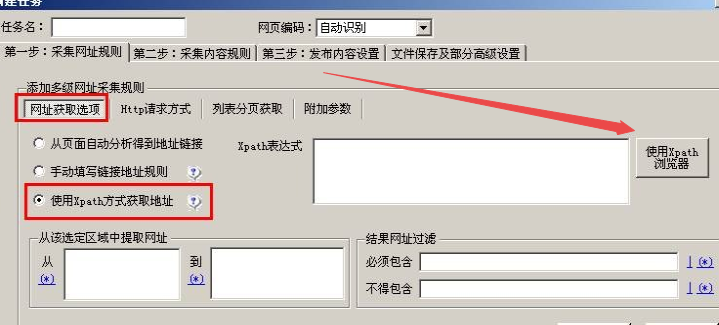
或者使用Xpath方式获取地址》使用Xpath浏览器。(参见XPath定位方法)



评论