如果要做下载站,需要批量采集目标网站的下载资源,用火车头采集器进行批量下载采集可以参考一下文章:
最近遇到个问题,能够得到文件真实的下载地址(地址有加密),用浏览器打开能够直接下载,试过用迅雷批量下载但得到的都是php文件,如果只有一个两个文件还好说用浏览器直接进行下载就ok了,但地址很多怎么办?今天教大家如何通过火车头采集器进行批量下载呢?
一般来说我们采集一个网站的文件的正常思路是这样的:
1、获取具体的分类列表页地址,从而获取内容页地址;
2、获取下载页地址,最后在下载页获取最终的下载地址进行下载
上面的思路是正常的思路,但最近碰到的这个问题有点棘手,只能通过其他方式在下载页里面获取了最终的下载地址(虽然这个最终下载地址是经过加密了的),下载地址通过人工也可以复制到浏览器进行下载,品自行也找到了简单的办法,通过一次性批量打开这些下载地址,然后网页可以批量打开,然后文件可以自动保存到同一个文件夹。但想通过或头采集器解决问题如何做呢?
想到了曾经写过一篇文章火车头采集器用正则提取方式获取当前页面URL,所以我们可以通过获取当前网址链接的方式采集当前网址链接作为文件下载链接在火车采集器里头进行批量下载。
需要注意的就是,根据前面的思路来的说,这样做采集到的分类页和内容页,包括最终的文件下载链接全是一个地址,不过这个不影响我们进行批量采集下载。
具体在火车头采集器里面可以进行如下设置:
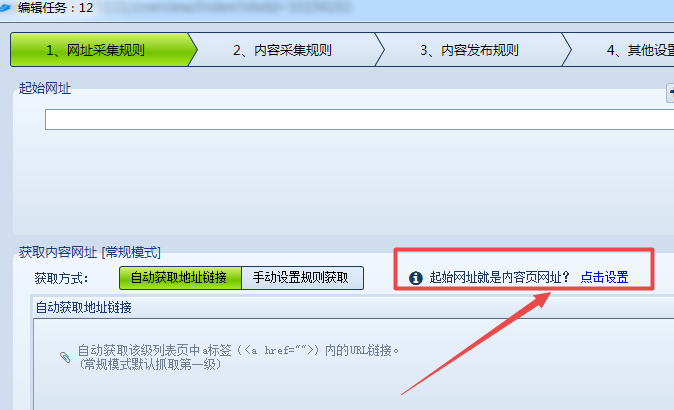
在网址采集规则下面设置“起始网址就是内容页网址”
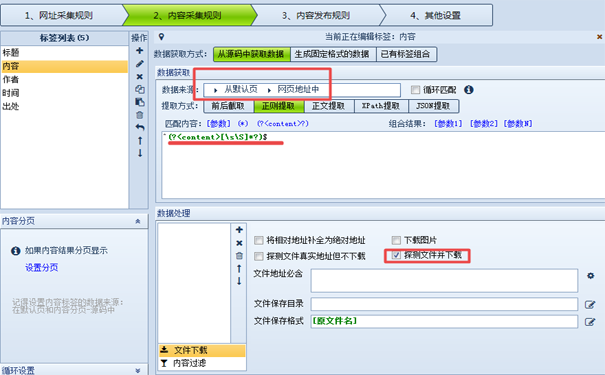
在内容采集规则下面设置“数据来源”、“匹配内容”和“文件下载”如下:
正则提取的代码请参照火车头采集器用正则提取方式获取当前页面URL进行设置。
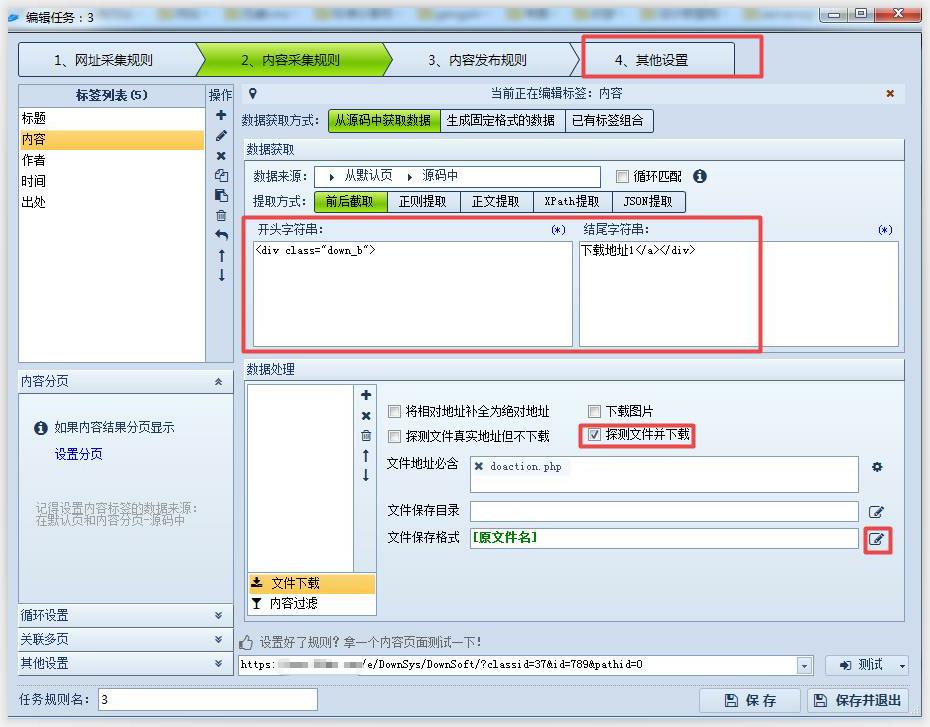
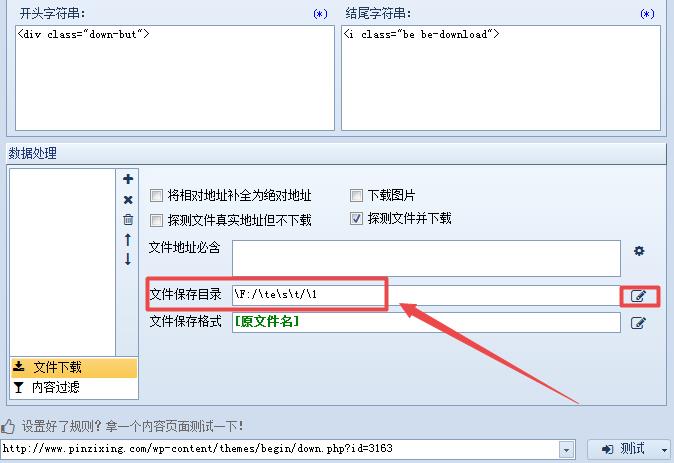
上面圈出来了几个设置的关键参数,其他参数设置根据需要进行设置。以上就是关于火车头采集器如何根据下载链接批量下载文件的所有内容,有问题的朋友欢迎一起交流。

评论